Content Based Image Retrieval - Google and Similar Image Search
I was very interested to see Google experimenting with visual similarity in still images, what I usually call Content Based Image Retrieval or CBIR.
Google Labs have just launched an image search function based on visual similarity - Google Similar Images. This new offering allows searchers to start with an initial image and then find other images that look like their example picture.
I've been reviewing these type of systems on and off since the early '90s. They've always offered much, but I never saw any evidence that the delivery matched the hype.
I've always found that using pictures instead of text to find images works best on simple 2d images: carpet patterns, trademarks, simple shapes, colours and textures. Finding objects in images was always a struggle, and looking for abstract concepts: fear, excitement, gloom, isolation, solitude.. was never been more than a vague possibility. Over the years a lot of work has been done in this area, and the search results I've seen have started to improve, but this technology is still young, and in my personal opinion still rarely delivers what most users want, need and expect.
Looking at Google Similar Images, I wonder how much of the back-end is pure content based image retrieval (CBIR), how much is using metadata in some way, and how the two are interacting? One thing that appears to be helping to often show a tight first page of results, is simply pulling the same image from different sites. I also noticed that the 'similar images' option is not available for all images - which makes me wonder why? Have some images been processed in ways that others haven't?

Diving right into the experience, I entered a query for a place in the UK and didn't see any image results with the 'Similar Images' option. I wonder whether this is to do with the presence of the results on UK websites?
I persevered, and found some interesting images and got some interesting results.
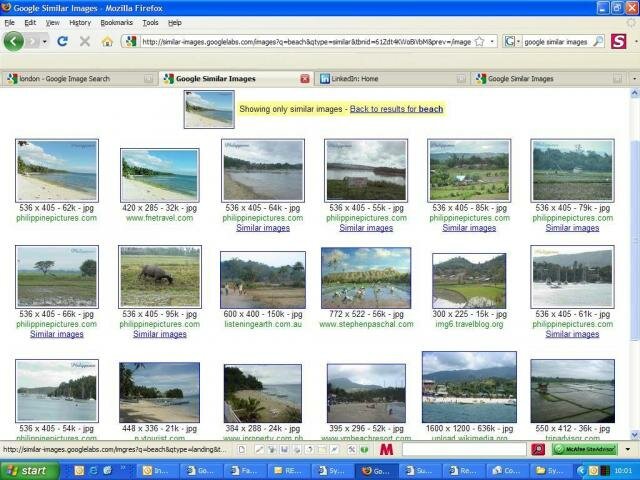 I started with a fairly standard image of a beach scene, always a favourite with testers. As you can see I got a pretty good first screen back. However, the 5th and 6th image on the top row show no sea or beach, neither do the first three images on the second row.
I started with a fairly standard image of a beach scene, always a favourite with testers. As you can see I got a pretty good first screen back. However, the 5th and 6th image on the top row show no sea or beach, neither do the first three images on the second row.

I moved on to an image of what looks like equipment at the top of a pole.
The results were much more mixed: studio shots of objects, fighting people, trucks etc. No images were returned that I would consider similar to the example picture.

Interesting results came from a similarity query on a clock face. A couple of the first results hit the mark, then the results set degenerated into image similarity based more on the colour and the black background than anything else.
 My last attempt, before morning coffee called, was an image of a country road. I was hoping that the clear roadway might produce a pretty precise results set. However, I was a little disappointed by what I saw.
My last attempt, before morning coffee called, was an image of a country road. I was hoping that the clear roadway might produce a pretty precise results set. However, I was a little disappointed by what I saw.
The first results page only produced one vague road on the bottom row, with most of the similarity seemingly related to colours instead of objects.
From my less than scientific dip into this Google Labs offering, it looks like the highlighted images on the Google Similar Images home page produce good results - better results than I've seen other systems come up with. Many other image queries are sure to also produce results which may well impress. However, many of the results I saw did not match the initial level of accuracy I saw from the highlighted home page pictures.
I don't want to be picky, this is still a prototype after all, and well done to Google for introducing a wider audience to this type of image search. Hopefully, after more work, the results will increasingly make more sense to people, the access points offered to depicted content and conceptual aboutness will improve and more images will be more findable for more people.
Until that time, visual search without text will help with image findability, but text, metadata, and controlled vocabulary applied to images by people is for me still king, and will continue to offer the widest and deepest access to images for a long time to come.
Ian